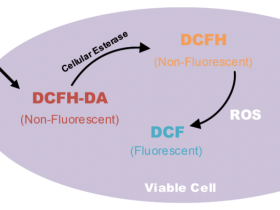
尽管我们对基因组的知识与日俱增,而且是巨大的飞跃,我们有时也需要提醒自己,DNA在1869年首次被分离,但它的分子结构直到1953年才被确定,直到1983年,PCR反应才对科学界产生了影响。所以即时飞速发展,我们仍然是基因领域的婴儿,当你在分析整个基因组时,你会强烈感觉到这个事实。基因变异的分类是基因组学中一个特别具有挑战性的领域。基因变异就是对给定DNA序列的改变,基因变异可以是良性的,致病的,或者是未知的。
为什么研究和分类这些变异很重要? 虽然许多基因变异不会转化为疾病或易感疾病,但也有一些与严重疾病有关,如各种癌症、血友病、神经纤维瘤病和早衰症(一种以加速老化为特征的疾病)。因此,对基因变异进行分类是极其重要的,因为知道它们的生理影响可能有助于区分健康个体和那些易患某些疾病的人,例如癌症。这可能有助于筛查项目、先发制人的医学和更好的患者预后。
为什么很难对基因变异进行分类? --- 我们每个人DNA中都储存着大量的信息。
- 人类有46条染色体,23对,是二倍体生物。我们可以把它看作是23条遗传自我们母亲的染色体,23条染色体遗传自我们的父亲。
- 据估计,人类大约有2万个蛋白质编码基因(然而,随着每天都有新的信息出现,这个数字正在进化)。
- 98%的基因组由不编码蛋白质的非编码DNA组成。它不会转化成氨基酸序列,但并不意味着它变得无关紧要,控制细胞基本细胞功能的调控序列位于非编码DNA中。这些基因序列的变异可能会严重影响机体的稳态。
- 我们的基因组大小是6,469.66万碱基对,这是储存在我们DNA中的大量信息。
- 个体之间的差异很小,每个人的基因组略有不同。因此,你必须能够区分低代表的多态性和可能导致疾病的基因变异。
科学家们一直致力于基因变异的研究,数以百计的人类基因组已经被测序,有许多公共数据库中有许多已知的与许多疾病有关的基因变异。还有一些功能研究试图破译某些基因变异对产生的蛋白质的影响,那些不能正常运作的蛋白质可能会导致疾病。本文介绍一个研究基因变异的工具—Ensembl数据库。
Ensembl是开始你的基因变异分析旅程的一个很好的方法,这个数据库可以让你接触到来自许多物种的数千个基因。你可以在方框区域输入基因的名字,表现型,或者其他任何术语。Ensembl会给你很多关于你的基因或表现型的信息,同时也提供一些其他资源的链接,比如UniProt和NCBI。
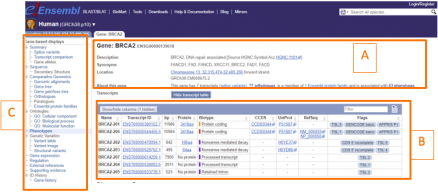
在搜索目的基因之后,将会得到一个如下的输出页面。在这里,你将找到基因的描述,别名(A),基因组的位置(B),以及其他重要的信息,包括相关的表型(C)。
你还将看到一个转录表(B),在其中可以找到目的基因的转录本。在这个表格中,你将发现蛋白质编码的转录本、非编码转录本和拼接基因变异。在Biotype专栏中,您将找到一个颜色方案分类,金色和一致编码序列(CCDS)的转录本都是经过审查的高质量的转录本,蓝色的是非编码转录本,而红色的或者直接来自Ensembl的自动标注通道,或者Vega/Havana的人工管理。
更重要的是,它告诉你哪些转录本是蛋白质编码,并提供它们的NCBI参考序列。例如BRCA2 基因, 在RefSeq 栏有NCBI 参考序列,NM_000059和NP_000050. NM_ 代表mRNA, NP_ 代表蛋白, 打开超链接,你将被带到NCBI核苷酸数据库中,以获得特定的mRNA/蛋白质。在这里,你会发现FASTA序列,文献提到的序列,外显子和作者等信息。
在左边的栏上(C),你将会有许多选择引导你获取宝贵的信息,例如序列、比较基因组学、相关的表型(包括已知的基因变体)。